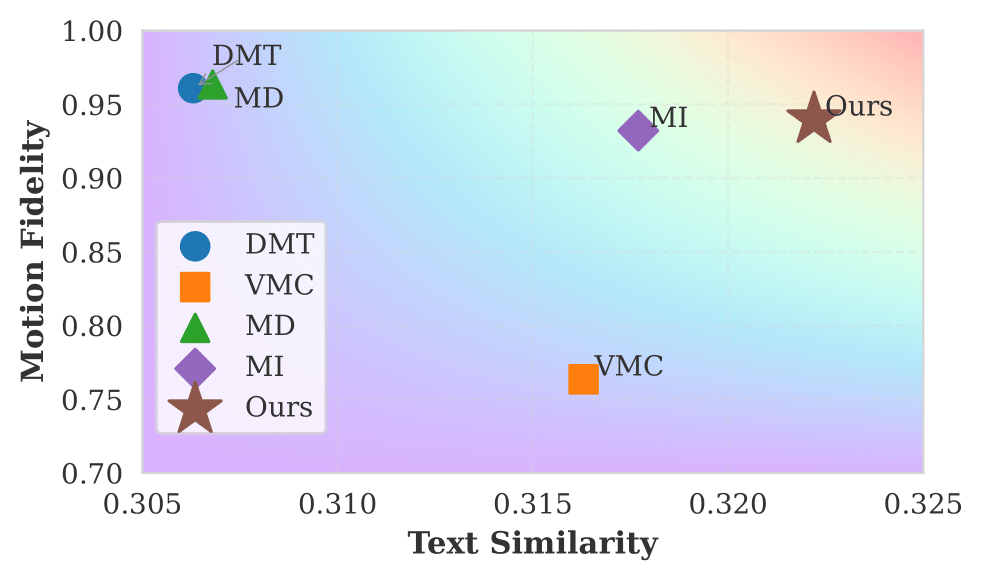
Method Overview
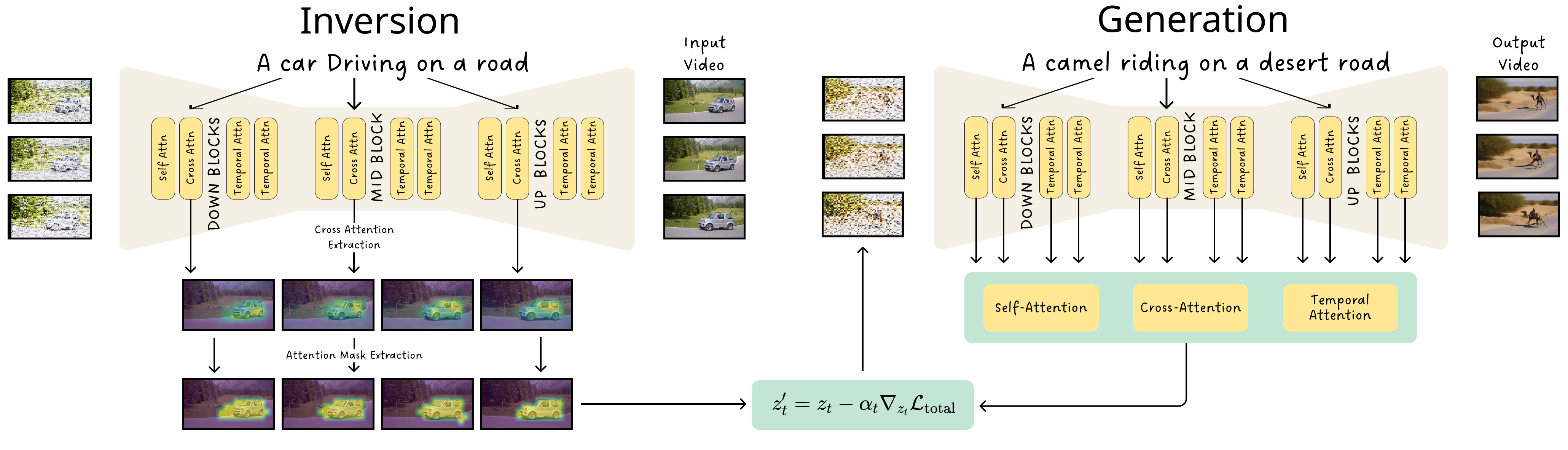
Our invert-then-generate method operates in two main stages: (1) Inversion, where DDIM inversion is used to extract latent representations and cross-attention maps from the original video, generating target masks that capture the subject's motion and spatial details; (2) Generation, where these masks and a text prompt guide the creation of a new video, aligning with the original video's motion dynamics and spatial layout while adhering to the semantic content of the prompt.